The fastest JS color library
Recently I spent some time optimizing the performance of our color manipulation code at work, and I’m fairly gruntled with the results so I’m releasing the library—color-bits—as a standalone as I think it can be useful for other use-cases. I wanted to dive here a bit more in depth into what makes it fast, as it ties well into my last post on performance optimization, and I’ll also be presenting a few benchmarks to illustrate the points.
1. Representation
In javascript the usual way to store RGBA colors would be something like this:
const color = { red: 0, green: 0, blue: 0, alpha: 1.0 }This representation is idiomatic and readable, but it also implies allocating a new heap object for each color. Knowing that RGBA colors go from #00000000 to #ffffffff (or in others words, the numbers from 0x0000000 to 0xffffffff) and that it’s 32 bits of data, we only really just need a single number value to encode those few bits.
Lucky us, that’s precisely the amount we have available through javascript bitwise operators:
const color =
(red << 24) |
(green << 16) |
(blue << 8) |
(alpha << 0)So let’s jump quickly in a benchmark to compare how the two approaches fare. In the following example, we fill a 100-length array with some shades of blue. Why a 100-length array and not just one big array with all the colors? Because it reflects what happens in a production context. You have colors going through the system, then those colors are discarded. Those discarded values must then be processed by the garbage collector, which explains…
// 1. object
const newColor = (blue) => ({
red: 0,
green: 0,
blue: blue,
alpha: 1.0,
})
const colors = new Array(100)
for (let i = 0; i < 100_000; i++) {
const index = i % 100
colors[index] = newColor(index)
}// 2. number
const newColor = (blue) =>
( 0 << 24) |
( 0 << 16) |
(blue << 8) |
( 255 << 0)
const colors = new Array(100)
for (let i = 0; i < 100_000; i++) {
const index = i % 100
colors[index] = newColor(index)
}It’s interesting to take a look at the stack traces for that benchmark as well. On the left is the object representation case, and on the right the number one. As we can see, the object one is constantly creating pressure for the garbage collector—each of those ticks is a “Minor GC” entry. Creating objects is expensive!
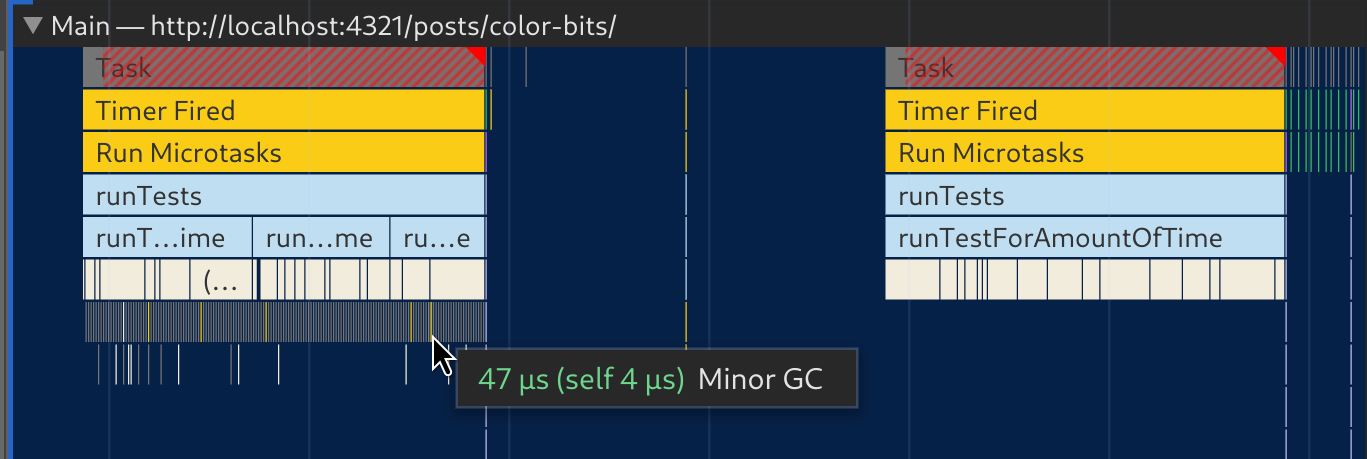 Stack traces for the object vs number benchmark
Stack traces for the object vs number benchmark
So let’s just use number values and…
All is good, right?
As I was happily piping those numbers through the test code, I realized to my big disappointment that javascript bitwise operators operate on 32-bits…signed.
So instead of 0xff << 24 being equal to 0xff000000, it equals -0x1000000. Our precious bits are all mangled by the bitwise operators! As I was running through my mind for solutions, my first thought was obviously to cast back the results from int32 to uint32. After all, it’s not more complicated than this:
function cast(int32Value) {
return int32Value >>> 0
}As a reminder, all bitwise operators turn their values into int32 numbers, except for >>> which is the “unsigned right shift” operation and the only one that operates on uint32 values.
So I was quite unhappy about adding more instructions, but hey, at least it’s still all bitwise operations on numbers, which are pretty cheap. Right?
Well the more I benchmarked, the more I found that solution to be unsatisfying. The problem isn’t merely the additional operation, it’s also that some particular engine applies a particular performance optimization that speeds up numbers up to… the 32-bits signed range. Namely, V8, the one that runs on 70% of browsing devices, and that powers NodeJS. So as soon as a color would overflow the int32 range (in other words, any color greater than or equal to 0x80000000), the whole codebase would slow down by a substantial factor! Red-ish colors were more expensive than blue-ish or green-ish colors, and it didn’t sit well with me. So let’s dive into what’s happening.
Number representation in V8
In a common device, passing values up to 64-bits is cheap because you can pass the value through CPU registers directly—their length is 64-bits. Values or objects above that size must be stored in memory, and passed as a (64-bits) pointer to that location. And pointers normally should make up all of JS values, because the garbage collector also needs to scan the heap for pointers to figure out which objects are not referenced anymore and can be freed. If there were numbers mixed with pointers, the GC wouldn’t be able to know if the value is a pointer or a number.
But 64-bits of pointer location, that’s a lot of bytes, and maybe we don’t really need all those addresses. So V8 says we’ll use one of those bits to tag if the value is a pointer or a number, and if it’s a number, we’ll store 32-bits of data in there, and we’ll call that a “Smi” because it’s a beautiful name.
tag -->|
|----- 32 bits -----|----- 32 bits -----|
Pointer: |________________address_______________1|
Smi: |____int32_value____|0000000000000000000|So there you go, that’s why you don’t want to go over the int32 range in V8. If your number overflows the int32 range, it becomes a pointer to a number value elsewhere in the heap. We can run a benchmark to make sure that’s the case. This is an example where we just add up the same value a bunch of times, but it’s either inside the Smi range, or outside. I’m going to include the numbers instead of a live one because I want to show the performance across engines, but the code is available here if you want to run it yourself:
> node ./index.js ./benchmarks/integers.js
### node: v22.7.0 ###
adding 2^31 - 1: ############################## 100.00% (1,685,399 ops)
adding 2^31 + 1: #####################......... 72.36% (1,219,483 ops)
### bun: 1.1.26 ###
adding 2^31 - 1: ############################## 100.00% (2,184,201 ops)
adding 2^31 + 1: #####......................... 18.77% (409,935 ops)
### gjs: 1.80.2 ###
adding 2^31 - 1: ############################## 100.00% (1,169,879 ops)
adding 2^31 + 1: ##################............ 62.74% (733,938 ops)This should be taken with a grain of salt because it’s a microbenchmark, but it still makes it painfully clear that overflowing the int32 range even by a tiny +1 makes a significant different across all engines for math operations. I don’t know enough about the other engines (bun is JSC-based, and gjs is SpiderMonkey-based by the way) to explain why it has so much of an influence, but while we’re here we might as well look into…
Number representation in JSC/SpiderMonkey
Both engines use variations of a technique called NaN-boxing. Double values, also known as float64 or f64 in more pragmatic languages, or IEEE-754 in technical terms, is what the EcmaScript spec defines as number, and they are encoded in 64-bits as such:
1 bit sign
|-|-- 11 bits ---|------------ 52 bits ---------------|
|±|___exponent___|_____________mantissa_______________|The neat trick is, float64 encoding defines NaN as any 64-bits pattern where the exponent bits are all set to 1 and the mantissa is non-zero. So for example, both 0b0_11111111111_1000... and 0b0_11111111111_0100... represent NaN, and so forth. Instead of wasting those values, the engine can pick a single way to represent NaN, and use the rest of those bits to put pointers, integers, etc.
As a sidenote, this is also the reason why Number.MAX_SAFE_INTEGER equals 2^53 - 1, that’s as much precision as float64 allows. The exponent uses the 11 other bits that make it to a 64 bits total.
But I’m digressing, so let’s go back to the issue.
So how do we use int32?
As it became apparent that with the language and all the engines conspiring against me, I wasn’t going to get any uint32 anytime soon. That’s when I realized the very simple solution that had been there all along: do nothing.
Let me recap how negative numbers and two’s complement work. Taking a single byte (a uint8 value) for simplicity, here is how each bit relates to its value:
Index: | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|------|-----|-----|-----|-----|-----|-----|-----|
Value: | -2^7 | 2^6 | 2^5 | 2^4 | 2^3 | 2^2 | 2^1 | 2^0 |So for the following bit patterns, the corresponding values are:
| Bit | ||||||||
|---|---|---|---|---|---|---|---|---|
| Value | 0 0 | 0 0 | 0 0 | 0 0 | 0 0 | 2^2 2^2 | 0 0 | 2^0 2^0 |
| Total | 5 | |||||||
And for negative values, if we set the high bit:
| Bit | ||||||||
|---|---|---|---|---|---|---|---|---|
| Value | -2^7-2^7 | 0 0 | 0 0 | 0 0 | 0 0 | 0 0 | 0 0 | 0 0 |
| Total | -128 | |||||||
And a last one, for -1:
| Bit | ||||||||
|---|---|---|---|---|---|---|---|---|
| Value | -2^7-2^7 | 2^6 2^6 | 2^5 2^5 | 2^4 2^4 | 2^3 2^3 | 2^2 2^2 | 2^1 2^1 | 2^0 2^0 |
| Total | -1 | |||||||
So why pick a scheme like two’s complement instead something more simple? After all, float64 encoding uses the first bit to signal +/-, isn’t that more simple? The last bit pattern here might have given you a clue. The idea behind two’s complement is that for some operations like say addition, we don’t need separate machine instructions for signed & unsigned values. The bits stay the same, but their interpretation changes. So for example, if you subtract 1 from 0b00000000, the bits would be 0b11111111 in both signed mode (where the value is 255) and unsigned mode (where the value is -1). Using this convention simplifies CPUs, which in turns allows them to be leaner & faster. This means that when you compile in a native language a data type like u32 or i32, the type disappear after compilation and the CPU only sees untyped bits. Some operations still require special handling for signed/unsigned numbers, but in those cases the instruction itself will be typed, not the data. For example, x86 has the MUL instruction for unsigned multiplication and IMUL for signed multiplication.
I hope this all explains my previous epiphany about doing nothing. Our bits were never mangled by bitwise operators, the bits were where they were supposed to be all along. If you 0xff << 24, the underlying bit pattern will still be 0b111111110000....0000 regardless if the number is interpreted as signed or unsigned.
I think it’s a very normal thing to reach for uint32, it’s the logical representation for 4 packed bytes. But in the limited context of javascript, going for what is available instead is the better option. I’ve seen other libraries as well do the same mistake, for example I was reading react-spring’s color handling code the other day, and I saw that they too had gone for the cast (>>> 0) to turn their values into the more logical uint32 format. But introducing all those int32 values all over the place incurs a performance penalty that propagates through any function that handles those values, and in a color manipulation library, that’s all of the functions.
2. Parsing
Satisfied with the color representation, I went on to look at the next most expensive operation in a color library. I won’t go into details into formats others than #rrggbbaa because for the other ones (rgba(), hsl(), color(display-p3, ), etc), anything other than regex parsing was suboptimal. Yes I tried a standard recursive descent top-down parser, unfortunaly this is javascript, and that sort of work is better left to the engine.
However, I had a feeling that hexadecimal parsing in particular could be improved.
Let’s take for example a naive regex approach:
const pattern = /#(..)(..)(..)(..)/
function parseHex_regex(color) {
const m = color.match(pattern)
return (
(parseInt(m[1], 16) << 24) |
(parseInt(m[2], 16) << 16) |
(parseInt(m[3], 16) << 8) |
(parseInt(m[4], 16) << 0)
)
}The problem with such an approach is that we would be creating a lot of allocations, the return value of RegExp.prototype.match being quite heavy—it’s an array of strings with custom fields. As we’ve seen in the first benchmark, avoiding object allocations is crucial to maintain a good performance.
So a good iteration on that to avoid the fat result array would be something like this:
function parseHex_slice(color) {
return (
(parseInt(color.slice(1, 3), 16) << 24) |
(parseInt(color.slice(3, 5), 16) << 16) |
(parseInt(color.slice(5, 7), 16) << 8) |
(parseInt(color.slice(7, 9), 16) << 0)
)
}But the problem is that even if we got rid of the fat result array, the .slice() calls are still allocating 4 strings, and those strings are going to create more GC pauses.
The only solution to extract characters of a string as numbers rather than strings is .charCodeAt(), so that’s what I picked to use for my fast parsing implementation. There are two techniques that I explored to turn those characters into their hexadecimal values, both of which I found on Daniel Lemire’s blog (where I somehow always end up when researching obscure optimization problems). The first one is to use a mathematical function, and the second one is to use a lookup array. Here is a javascript port of both:
// Transform char code to its hexadecimal value
function x(c) { return (c & 0xf) + 9 * (c >> 6) }
function parseHex_function(color) {
const r = x(color.charCodeAt(1)) << 4 | x(color.charCodeAt(2))
const g = x(color.charCodeAt(3)) << 4 | x(color.charCodeAt(4))
const b = x(color.charCodeAt(5)) << 4 | x(color.charCodeAt(6))
const a = x(color.charCodeAt(7)) << 4 | x(color.charCodeAt(8))
return (
(r << 24) |
(g << 16) |
(b << 8) |
(a << 0)
)
}// Transform char code to its hexadecimal value,
// but as a lookup array.
const _ = 0
const X = [
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, 0, 1, 2, 3, 4, 5, 6, 7, 8,
9, _, _, _, _, _, _, _, 10, 11, 12, 13, 14, 15, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, 10, 11, 12, 13, 14, 15, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _
]
function parseHex_table(color) {
const r = X[color.charCodeAt(1)] << 4 | X[color.charCodeAt(2)]
const g = X[color.charCodeAt(3)] << 4 | X[color.charCodeAt(4)]
const b = X[color.charCodeAt(5)] << 4 | X[color.charCodeAt(6)]
const a = X[color.charCodeAt(7)] << 4 | X[color.charCodeAt(8)]
return (
(r << 24) |
(g << 16) |
(b << 8) |
(a << 0)
)
}With all that setup, let’s benchmark to see which one is the fastest:
// setup
const pattern = /#(..)(..)(..)(..)/
function parseHex_regex(color) {
const m = color.match(pattern)
return (
(parseInt(m[1], 16) << 24) |
(parseInt(m[2], 16) << 16) |
(parseInt(m[3], 16) << 8) |
(parseInt(m[4], 16) << 0)
)
}
function parseHex_slice(color) {
return (
(parseInt(color.slice(1, 3), 16) << 24) |
(parseInt(color.slice(3, 5), 16) << 16) |
(parseInt(color.slice(5, 7), 16) << 8) |
(parseInt(color.slice(7, 9), 16) << 0)
)
}
// Char code to its hex value
function x(c) { return (c & 0xf) + 9 * (c >> 6) }
function parseHex_function(color) {
const r = x(color.charCodeAt(1)) << 4 | x(color.charCodeAt(2))
const g = x(color.charCodeAt(3)) << 4 | x(color.charCodeAt(4))
const b = x(color.charCodeAt(5)) << 4 | x(color.charCodeAt(6))
const a = x(color.charCodeAt(7)) << 4 | x(color.charCodeAt(8))
return (
(r << 24) |
(g << 16) |
(b << 8) |
(a << 0)
)
}
// Char code to its hex value, but as a table
const _ = 0
const X = [
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, 0, 1, 2, 3, 4, 5, 6, 7, 8,
9, _, _, _, _, _, _, _, 10, 11, 12, 13, 14, 15, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, 10, 11, 12, 13, 14, 15, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _,
_, _, _, _, _, _, _, _, _
]
function parseHex_table(color) {
const r = X[color.charCodeAt(1)] << 4 | X[color.charCodeAt(2)]
const g = X[color.charCodeAt(3)] << 4 | X[color.charCodeAt(4)]
const b = X[color.charCodeAt(5)] << 4 | X[color.charCodeAt(6)]
const a = X[color.charCodeAt(7)] << 4 | X[color.charCodeAt(8)]
return (
(r << 24) |
(g << 16) |
(b << 8) |
(a << 0)
)
}// setup
const N = 100_000
const colors = new Array(100)// 1. regex
for (let i = 0; i < N; i++) {
colors[i % 100] = parseHex_regex('#599eff80')
}// 2. slice
for (let i = 0; i < N; i++) {
colors[i % 100] = parseHex_slice('#599eff80')
}// 3. char + function
for (let i = 0; i < N; i++) {
colors[i % 100] = parseHex_function('#599eff80')
}// 4. char + table
for (let i = 0; i < N; i++) {
colors[i % 100] = parseHex_table('#599eff80')
}As you can see, both allocation-less versions run much faster than the naive ones. Daniel suggests that the table version runs faster than the function version in C, but as we’re running inside a javascript engine, our array lookups are considerably more expensive (due to bound checks and whatnot), so the final winner is parseHex_function.
3. Formatting
And for the final part, I looked into how to output those values as strings efficiently. In an ideal setting, color values wouldn’t need to be turned back to strings, but this is unavoidable as most APIs javascript interacts with are string-based.
The simple implementation I went for initially was the following one:
function format_simple(color) {
return `#${color.toString(16).padStart(8, '0')}`
}But I wasn’t happy with the results. One thing I wanted to avoid is the temporary string allocations, the ones returned by toString and padStart. I also wanted to avoid as much as possible calling javascript string functions like those ones because I usually find that them to be less efficient than pure-javascript ones. It could be for a variety of reasons (e.g. the spec requiring expensive checks/conversions) but I don’t know enough about to explain it.
So I pulled inspiration from the previously presented function from Daniel’s blog, and went for a lookup array that converts hexadecimal values to their string representation:
// ['00', '01', ..., 'fe', 'ff']
const X =
Array.from({ length: 256 })
.map((_, i) => i.toString(16).padStart(2, '0'))
function format_table(color) {
return (
'#' +
X[color >> 24 & 0xff] +
X[color >> 16 & 0xff] +
X[color >> 8 & 0xff] +
X[color >> 0 & 0xff]
)
}And here is a final benchmark to validate that we’re indeed running faster:
// setup
function format_simple(color) {
return `#${color.toString(16).padStart(8, '0')}`
}
// ['00', '01', ..., 'fe', 'ff']
const X =
Array.from({ length: 256 })
.map((_, i) => i.toString(16).padStart(2, '0'))
function format_table(color) {
return (
'#' +
X[color >> 24 & 0xff] +
X[color >> 16 & 0xff] +
X[color >> 8 & 0xff] +
X[color >> 0 & 0xff]
)
}// setup
const N = 100_000
const colors = new Array(100)// 1. simple
for (let i = 0; i < N; i++) {
colors[i % 100] = format_simple(0x0f0f0f)
}// 2. table
for (let i = 0; i < N; i++) {
colors[i % 100] = format_table(0x0f0f0f)
}4. Benchmarks
So with all that completed let’s see how it compares to other existing color libraries on NPM. I re-used the benchmarking code from colord and slightly modified it to showcase how it performs for the case it was optimized for (hexadecimal strings), so the benchmark code consists of parsing a hex color string, modifying its opacity, and converting it back to a hex color string.
| Library | Operations/sec | Relative speed |
|---|---|---|
| color-bits | 22 966 299 | fastest |
| colord | 4 308 547 | 81.24% slower |
| tinycolor2 | 1 475 762 | 93.57% slower |
| chroma-js | 846 924 | 96.31% slower |
| color | 799 262 | 96.52% slower |
Tada ✨ About 5x faster than the 2nd place, colord, which had the previous claim to the fastest color library. I haven’t included the benchmark for non #rrggbbaa colors like rgb() or hsl(), but color-bits is still around 2x faster than the 2nd place even in those cases.
5. Closing thoughts
I think avoiding memory allocations is one of the easiest and most impactful ways to speed up a program. Javascript is a very convenient language, allocating a new object can be as simple as typing {}, [] or { ...newObject }, and I love the expressivity it brings. But it’s a double-edged sword, because it makes those memory allocations less apparent. It’s also hard to notice how those allocations impact your program, because allocating memory is somewhat fast, but managing and freeing allocations are the actually expensive operations. And that will appear as a single blob of Minor GC or Major GC entries in your stack traces. Most of the time, when I profile a program, Minor GC is in the top 5 entries! But it’s so easy to just dimiss it as “stuff the engine needs to do anyway”. That’s not the case. Any garbage to collect is garbage you have created. If you want to build fast, responsive, delightful software, you need to architect it to avoid creating and re-creating objects constantly like some frameworks do (yes, I’m looking at you React). Pick instead proper frameworks and solutions that are built with good fundamentals (why won’t the world adopt SolidJS already?).
I hope this wasn’t too boring. As always, feel free to email any comments, corrections or questions, link in the footer.
You can follow me on github or subscribe to the RSS feed if you want to see more performance-related stuff.
NPM: https://www.npmjs.com/package/color-bits
Github: https://github.com/romgrk/color-bits